class: center, middle, inverse, title-slide # The language of models ### Dr. Çetinkaya-Rundel ### October 5, 2017 --- class: center, middle # Getting started --- ## Getting started - Any questions from last time? - Today: Modeling the relationship between variables - Focus on *linear* models (but remember there are other types of models too!) --- ## Data: Paris Paintings ```r library(tidyverse) # ggplot2 + dplyr + readr + and some others library(broom) ``` ```r pp <- read_csv("data/paris_paintings.csv", na = c("n/a", "", "NA")) ``` <div class="question"> What does the data/ mean in the code above? Hint: Where is the data file (the csv) located? </div> --- ## Prices <div class="question"> Describe the distribution of prices of paintings. </div> ```r ggplot(data = pp, aes(x = price)) + geom_histogram(binwidth = 1000) ``` 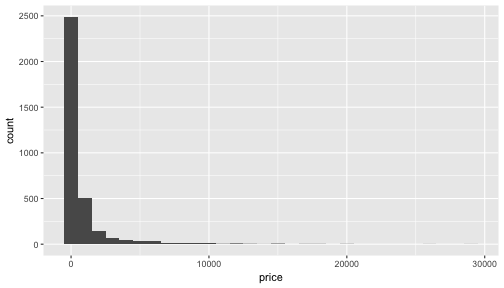<!-- --> --- class: center, middle # Modeling the relationship between variables --- ## Models as functions - We can represent relationships between variables using **functions** - A function is a mathematical concept: the relationship between an output and one or more inputs. - Plug in the inputs and receive back the output - Example: the formula `\(y = 3x + 7\)` is a function with input `\(x\)` and output `\(y\)`, when `\(x\)` is `\(5\)`, the output `\(y\)` is `\(22\)` ``` y = 3 * 5 + 7 = 22 ``` --- ## Height as a function of width ```r ggplot(data = pp, aes(x = Width_in, y = Height_in)) + geom_point() + stat_smooth(method = "lm") # lm for linear model ``` 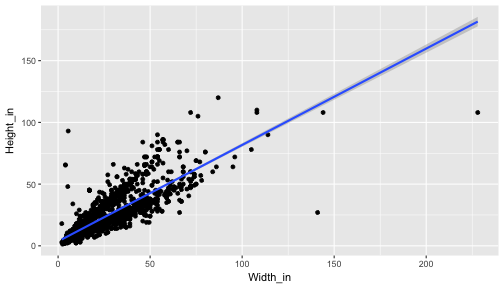<!-- --> --- ## Vocabulary - **Response variable:** Variable whose behavior or variation you are trying to understand, on the y-axis (dependent variable) - **Explanatory variables:** Other variables that you want to use to explain the variation in the response, on the x-axis (independent variables) - **Predicted value:** Output of the function **model function** - The model function gives the typical value of the response variable *conditioning* on the explanatory variables - **Residuals:** Show how far each case is from its model value - `\(residual = actual~value - predicted~value\)` - Tells how far above/below the model function each case is --- ## Residuals <div class="question"> What does a negative residual mean? Which paintings on the plot have have negative residuals? </div> 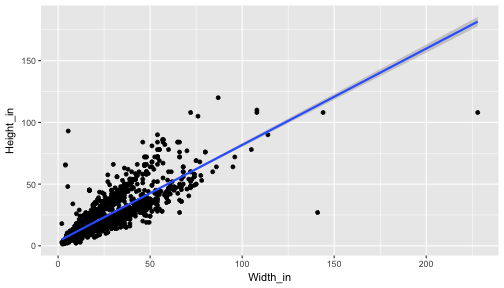<!-- --> --- ## Multiple explanatory variables <div class="question"> How, if at all, the relatonship between width and height of paintings vary by whether or not they have any landscape elements? </div> .pull-left[ 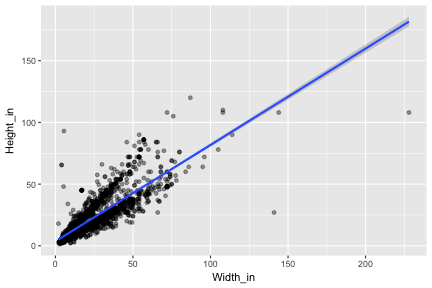<!-- --> ] .pull-right[ <!-- --> ] --- ## Just for reference... Here is the code for the two plots in the previous slide ```r # points not colored by landsALL type ggplot(data = pp, aes(x = Width_in, y = Height_in)) + geom_point(alpha = 0.4) + stat_smooth(method = "lm") ``` ```r # points colored by landsALL type ggplot(data = pp, aes(x = Width_in, y = Height_in, color = factor(landsALL))) + geom_point(alpha = 0.4) + stat_smooth(method = "lm") + labs(color = "landscape") ``` --- ## What's a `factor`? Factor is what R calls categorical variabkles. The `factor` function converts a variable to a factor. ```r class(pp$landsALL) ``` ``` ## [1] "integer" ``` ```r class(factor(pp$landsALL)) ``` ``` ## [1] "factor" ``` --- ## Models - upsides and downsides - Models can sometimes reveal patterns that are not evident in a graph of the data. This is a great advantage of modeling over simple visual inspection of data. - There is a real risk, however, that a model is imposing structure that is not really there on the scatter of data, just as people imagine animal shapes in the stars. A skeptical approach is always warranted. --- ## Variation around the model... is just as important as the model, if not more! *Statistics is the explanation of variation in the context of what remains unexplained.* - The scatter suggests that there might be other factors that account for large parts of painting-to-painting variability, or perhaps just that randomness plays a big role. - Adding more explanatory variables to a model can sometimes usefully reduce the size of the scatter around the model. (We'll talk more about this later.) --- ## How do we use models? 1. Explanation: Characterize the relationship between `\(y\)` and `\(x\)` via *slopes* for numerical explanatory variables or *differences* for categorical explanatory variables 2. Prediction: Plug in `\(x\)`, get the predicted `\(y\)` --- class: center, middle # Characterizing relationships with models --- ## Relationship between height & width ```r lm(Height_in ~ Width_in, data = pp) ``` ``` ## ## Call: ## lm(formula = Height_in ~ Width_in, data = pp) ## ## Coefficients: ## (Intercept) Width_in ## 3.6214 0.7808 ``` `$$\widehat{Height_{in}} = 3.62 + 0.78~Width_{in}$$` - **Slope:** For each additional inch the painting is wider, the height is expected to be higher, on average, by 0.78 inches. - **Intercept:** Paintings that are 0 inches wide are expected to be 3.62 inches high, on average. - Does this make sense? --- ## Relationship between height & landscape features ```r lm(Height_in ~ factor(landsALL), data = pp) ``` ``` ## ## Call: ## lm(formula = Height_in ~ factor(landsALL), data = pp) ## ## Coefficients: ## (Intercept) factor(landsALL)1 ## 22.680 -5.645 ``` `$$\widehat{Height_{in}} = 22.68 - 5.65~landsALL$$` - **Slope:** Paintings that have some landscape features are expected, on average, to be 5.65 inches shorter than paintings that don't have landscape features. - Compares baseline level (`landsALL = 0`) to other level (`landsALL = 1`). - **Intercept:** Paintings that don't have landscape features are expected, on average, to be 22.68 inches tall. --- ## Relationship between height and school ```r lm(Height_in ~ school_pntg, data = pp) ``` ``` ## ## Call: ## lm(formula = Height_in ~ school_pntg, data = pp) ## ## Coefficients: ## (Intercept) school_pntgD/FL school_pntgF school_pntgG ## 14.000 2.329 10.197 1.650 ## school_pntgI school_pntgS school_pntgX ## 10.287 30.429 2.869 ``` - When the categorical explanatory variable has many levels, they're encoded to **dummy variables**. - Each coefficient describes the expected difference between heights in that particular school compared to the baseline level. --- ## Correlation does not imply causation! Remember this when interpreting model coefficients --- class: center, middle # Prediction with models --- ## Predict height from width {.build} <div class="question"> On average, how tall are paintings that are 60 inches wide? \[ \widehat{Height_{in}} = 3.62 + 0.78~Width_{in} \] </div> ```r 3.62 + 0.78 * 60 ``` ``` ## [1] 50.42 ``` "On average, we expect paintings that are 60 inches wide to be 50.42 inches high." **Warning:** We "expect" this to happen, but there will be some variability. (We'll learn about measuring the variability around the prediction later.) --- ## Prediction vs. extrapolation <div class="question"> On average, how tall are paintings that are 400 inches wide? `$$\widehat{Height_{in}} = 3.62 + 0.78~Width_{in}$$` </div> <!-- --> --- ## Watch out for extrapolation! > "When those blizzards hit the East Coast this winter, it proved to my satisfaction that global warming was a fraud. That snow was freezing cold. But in an alarming trend, temperatures this spring have risen. Consider this: On February 6th it was 10 degrees. Today it hit almost 80. At this rate, by August it will be 220 degrees. So clearly folks the climate debate rages on."<sup>1</sup> <br> Stephen Colbert, April 6th, 2010 .footnote[ [1] OpenIntro Statistics. "Extrapolation is treacherous." OpenIntro Statistics. ] --- class: center, middle # Measuring model fit --- ## Measuring the strength of the fit - The strength of the fit of a linear model is most commonly evaluated using `\(R^2\)`. - It tells us what percent of variability in the response variable is explained by the model. - The remainder of the variability is explained by variables not included in the model. - `\(R^2\)` is sometimes called the coefficient of determination. --- ## Obtaining `\(R^2\)` in R - Height vs. width ```r m_ht_wt <- lm(Height_in ~ Width_in, data = pp) # fit and save glance(m_ht_wt)$r.squared # extract R-squared ``` ``` ## [1] 0.6829468 ``` Roughly 68% of the variability in heights of paintings can be explained by their widths. - Height vs. lanscape features ```r m_ht_land <- lm(Height_in ~ landsALL, data = pp) glance(m_ht_land)$r.squared ``` ``` ## [1] 0.03456724 ``` --- ## Hands on! See Slack for brief activity link.