class: center, middle, inverse, title-slide # Estimation via bootstrapping ### Dr. Çetinkaya-Rundel ### October 26, 2017 --- class: center, middle # Getting started --- ## Getting started - New teams - Why was my `anti_join` code broken last time? --- class: center, middle # Confidence intervals --- ## Confidence intervals A plausible range of values for the population parameter is a **confidence interval**. .pull-left[  ] .pull-right[  ] - If we report a point estimate, we probably won’t hit the exact population parameter. - If we report a range of plausible values we have a good shot at capturing the parameter. --- ## Variability of sample statistics - In order to construct a confidence interval we need to quantify the variability of our sample statistic. - For example, if we want to construct a confidence interval for a population mean, we need to come up with a plausible range of values around our observsed sample mean. - This range will depend on how precise and how accurate our sample mean is as an estimate of the population mean. - Quantifying this requires a measurement of how much we would expect the sample mean to vary from sample to sample. <div class="question"> 👤 Suppose you randomly sample 50 students and 5 of them are left handed. If you were to take another random sample of 50 students, how many would you expect to be left handed? Would you be surprised if only 3 of them were left handed? Would you be surprised if 40 of them were left handed? </div> --- ## Quantifying the variability of a sample statistic We can quantify the variability of sample statistics using - simulation: via bootstrapping (today) or - theory: via Central Limit Theorem (later in the course) --- class: center, middle # Bootstrapping --- ## Bootstrapping <img src="img/16/boot.png" style="float:right"> - The term **bootstrapping** comes from the phrase "pulling oneself up by one’s bootstraps", which is a metaphor for accomplishing an impossible task without any outside help. - In this case the impossible task is estimating a population parameter, and we’ll accomplish it using data from only the given sample. - Note that this notion of saying something about a population parameter using only information from an observed sample is the crux of statistical inference, it is not limited to bootstrapping. --- ## Rent in Manhattan On a given day, twenty 1 BR apartments were randomly selected on Craigslist Manhattan from apartments listed as "by owner" (as opposed to by a rental agency). ```r # Load packages library(tidyverse) # Load data manhattan <- read_csv("data/manhattan.csv") ``` --- ## Parameter of interest <div class="question"> 👤 Is the mean or the median a better measure of typical rent in Manhattan? </div> .small[ ```r ggplot(data = manhattan, mapping = aes(x = rent)) + geom_histogram(binwidth = 200) + labs(title = "Rent of one bedroom apartments in Manhattan") ``` <!-- --> ] --- ## Observed sample vs. bootstrap population .pull-left[  Sample median = $2350 😱 ] -- .pull-right[  Population median = ❓ ] --- ## Bootstrapping scheme 1. Take a bootstrap sample - a random sample taken with replacement from the original sample, of the same size as the original sample. 2. Calculate the bootstrap statistic - a statistic such as mean, median, proportion, slope, etc. computed on the bootstrap samples. 3. Repeat steps (1) and (2) many times to create a bootstrap distribution - a distribution of bootstrap statistics. 4. Calculate the bounds of the XX% confidence interval as the middle XX% of the bootstrap distribution. --- class: center, middle # Bootstrapping in R --- ## New package: `infer` For doing simulation based inference in R: ```r # install_github("andrewpbray/infer") library(infer) ``` Also, let's set a seed: ```r set.seed(20171026) ``` --- ## Generate bootstrap medians ```r rent_ci_med <- manhattan %>% # specify the variable of interest specify(response = rent) %>% # generate 15000 bootstrap samples generate(reps = 15000, type = "bootstrap") %>% # calculate the median of each bootstrap sample calculate(stat = "median") ``` Let's take a peek at `rent_ci_med` (the bootstrap distribution of medians): ```r str(rent_ci_med) ``` ``` ## Classes 'tbl_df', 'tbl' and 'data.frame': 15000 obs. of 2 variables: ## $ replicate: int 1 2 3 4 5 6 7 8 9 10 ... ## $ stat : num 2175 2350 2350 2350 2450 ... ## - attr(*, "response")= symbol rent ``` --- ## Visualize the bootstrap distribution ```r ggplot(data = rent_ci_med, mapping = aes(x = stat)) + geom_histogram(binwidth = 50) + labs(title = "Bootstrap distribution of medians") ``` <!-- --> --- ## Calculate the confidence interval ```r rent_ci_med %>% summarize(lower_bound = quantile(stat, 0.025), upper_bound = quantile(stat, 0.975)) ``` ``` ## # A tibble: 1 x 2 ## lower_bound upper_bound ## <dbl> <dbl> ## 1 2162.5 2875 ``` 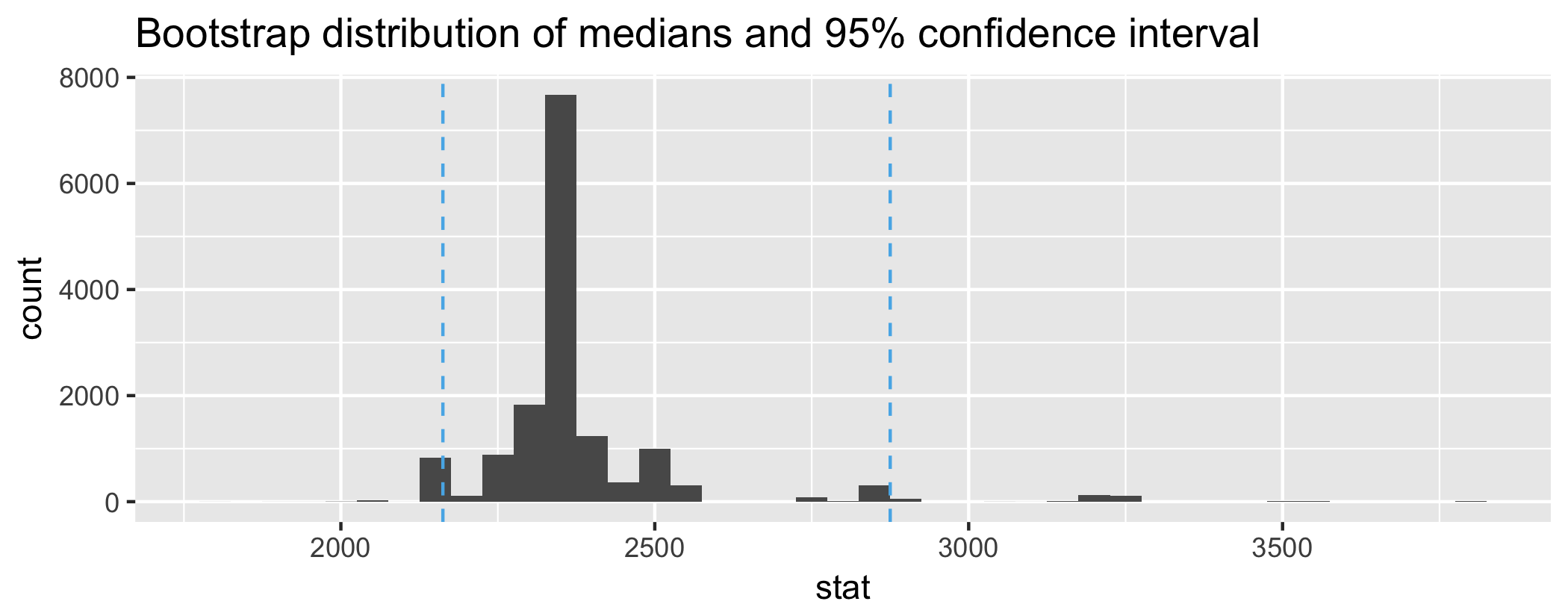<!-- --> --- ## Interpret the confidence interval <div class="question"> 👥 The 95% confidence interval for the median rent of one bedroom apartments in Manhattan was calculated as (2162.5, 2875). Which of the following is the correct interpretation of this interval? </div> (a) 95% of the time the median rent one bedroom apartments in this sample is between $2162.5 and $2875. (b) 95% of all one bedroom apartments in Manhattan have rents between $2162.5 and $2875. (c) We are 95% confident that the median rent of all one bedroom apartments is between $2162.5 and $2875. (d) We are 95% confident that the median rent one bedroom apartments in this sample is between $2162.5 and $2875. --- class: center, middle # Accuracy vs. precision --- ## Confidence level - Suppose we took many samples from the original population and built a 95% confidence interval based on each sample. - Then about 95% of those intervals would contain the true population parameter. - Commonly used confidence levels in practice are 90%, 95%, and 99%. <div class="question"> 👤 Which line represents which confidence level? </div> 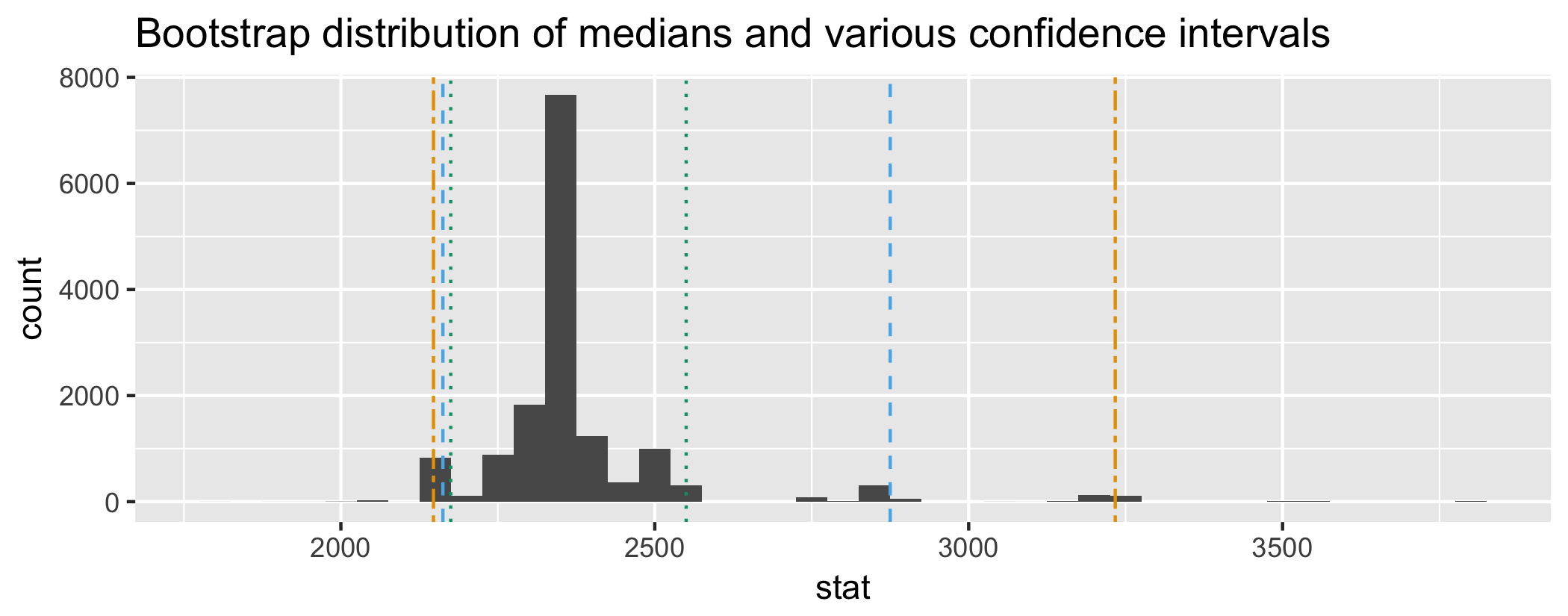<!-- --> --- ## Precision vs. accuracy <div class="question"> 👥 If we want to be very certain that we capture the population parameter, should we use a wider interval or a narrower interval? What drawbacks are associated with using a wider interval? </div> <br><br> -- <div class="question"> 👤 How can we get best of both worlds -- high precision and high accuracy? </div> --- ## Calculating confidence intervals at various confidence levels <div class="question"> 👥 How would you modify the following code to calculate a 90% confidence interval? How would you modify it for a 99% confidence interval? </div> ```r manhattan %>% specify(response = rent) %>% generate(reps = 15000, type = "bootstrap") %>% calculate(stat = "median") %>% summarize(lower_bound = quantile(stat, 0.025), upper_bound = quantile(stat, 0.975)) ```