---
title: "Web scraping part II"
subtitle: "Programming for Statistical Science"
author: "Shawn Santo"
institute: ""
date: ""
output:
xaringan::moon_reader:
css: "slides.css"
lib_dir: libs
nature:
highlightStyle: github
highlightLines: true
countIncrementalSlides: false
editor_options:
chunk_output_type: console
---
```{r include=FALSE}
knitr::opts_chunk$set(echo = TRUE, message = FALSE, warning = FALSE,
comment = "#>", highlight = TRUE,
fig.align = "center")
```
## Supplementary materials
Full video lecture available in Zoom Cloud Recordings
Additional resources
- [Web scraping cheat sheet](https://github.com/yusuzech/r-web-scraping-cheat-sheet/blob/master/README.md)
- `RSelenium` [website](http://ropensci.github.io/RSelenium/)
---
class: inverse, center, middle
# Recall
---
## Hypertext Markup Language
- HTML describes the structure of a web page; your browser interprets the
structure and contents and displays the results.
- The basic building blocks include elements, tags, and attributes.
- an element is a component of an HTML document
- elements contain tags (start and end tag)
- attributes provide additional information about HTML elements
---
## HTML vs. XML
.tiny.pull-left[
**HTML snippet**
```html
```
]
.tiny.pull-right[
**XML snippet**
```xml
Swim with a Mission
Wellington SP, West Shore Rd, Bristol, NH
http://www.swimnewfoundlake.com/
Jul 11, Sat
5 km, 10 km, 10 mi
```
]
---
## SelectorGadget
In CSS, selectors are patterns used to select the element(s) you want to style.
[SelectorGadget](https://selectorgadget.com/) makes identifying the CSS
selector you need as easy as clicking on items on a webpage.
---
## Web scraping workflow
1. Understand the website's hierarchy and what information you need.
--
2. Use SelectorGadget to identify relevant CSS selectors.
--
3. Read html by passing a url and subset the resulting html document using
CSS selectors.
```{r eval=FALSE}
read_html(url) %>%
html_nodes(css = "specified_css_selector")
```
--
4. Further extract attributes, text, or tags by adding another layer with
```{r eval=FALSE}
read_html(url) %>%
html_nodes(css = "specified_css_selector") %>%
html_*()
```
where `*` is `text`, `attr`, `attrs`, `name`, or `table`.
---
## Example with `html_table()`
http://www.tornadohistoryproject.com/tornado/North-Carolina/2017/table
.tiny[
```{r}
library(rvest)
library(tidyverse)
url <- "http://www.tornadohistoryproject.com/tornado/North-Carolina/2017/table"
nc_tornado <- read_html(url) %>%
html_nodes("#results") %>%
html_table(header = TRUE) %>%
.[[1]] %>%
janitor::clean_names() %>%
select(date:lift_lon)
glimpse(nc_tornado)
```
]
---
## Overview
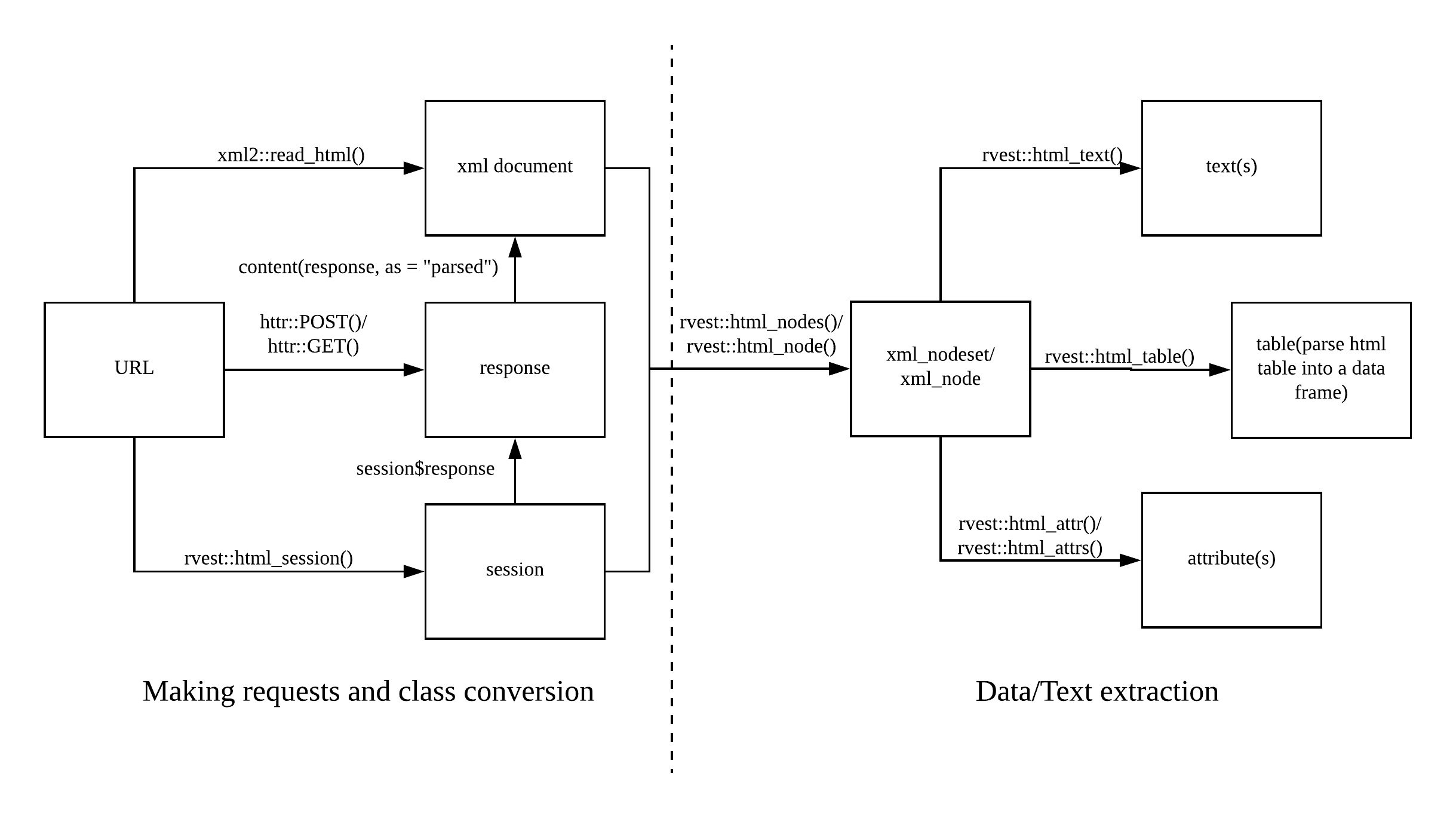
*Source*: https://github.com/yusuzech/r-web-scraping-cheat-sheet/blob/master/README.md
---
## Recall previous exercise
Go to http://books.toscrape.com/catalogue/page-1.html and scrape the first
five pages of data on books with regards to their
1. title
2. price
3. star rating
Organize your results in a neatly formatted tibble similar to below.
```{r eval=FALSE}
# A tibble: 100 x 3
title price rating
1 A Light in the Attic £51.… Three
2 Tipping the Velvet £53.… One
3 Soumission £50.… One
4 Sharp Objects £47.… Four
5 Sapiens: A Brief History of Humankind £54.… Five
6 The Requiem Red £22.… One
7 The Dirty Little Secrets of Getting Your Dream J… £33.… Four
8 The Coming Woman: A Novel Based on the Life of t… £17.… Three
9 The Boys in the Boat: Nine Americans and Their E… £22.… Four
10 The Black Maria £52.… One
# … with 90 more rows
```
---
class: inverse, center, middle
# Web scraping considerations
---
## Best practices
- Abide by a site's terms and conditions.
--
- Respect robots.txt.
- https://www.facebook.com/robots.txt
- https://www.wegmans.com/robots.txt
- https://www.google.com/robots.txt
--
- Cache your `read_html()` chunks. Isolate these chunks.
--
- Avoid using `read_html()` in code that is iterated.
--
- Do not overload the server at peak hours.
- Implement delayed crawls: `Sys.sleep(rexp(1) + 4)`
--
- If available, use a site's API.
--
- Do not violate any copyright laws.
---
## Other considerations
- Disguise your IP address.
- `httr::use_proxy()`
--
- Avoid scraping behind pages protected by log-in, unless it is permitted
by the site.
- `html_session()`
--
- Watch out for honey pot traps - invisible links to normal visitors,
but present in HTML code and found by web scrapers.
---
class: inverse, center, middle
# Beyond `rvest` and static sites
---
## Limitations of using `rvest` functions
- It is difficult to make your code reproducible long term. When a website or
the HTML changes, your code may no longer work.
- CSS selectors change
- Contents are moved
- Switch from HTML to JavaScript
--
- Websites that rely heavily on JavaScript
---
## What is JavaScript?
- Scripting language for building interactive web pages
- Basis for web, mobile, and network applications
- Every browser has a JavaScript engine that can execute JavaScript code.
- Chrome and Edge: V8
- Safari: JavaScriptCore
- Firefox: SpiderMonkey
--
If `read_html()` is meant for HTML, what can we do?
---
## Possible solutions
1. Use your browser's developer tools (Chrome is easiest)
2. Execute JavaScript in R
3. Use package `Rselenium` or other web drivers
- http://ropensci.github.io/RSelenium/
--
We'll focus on the first option...
>In order for the information to get from their server and show up on a page in
your browser, that information had to have been returned in an HTTP response
somewhere.
It usually means that you won’t be making an HTTP request to the page’s URL
that you see at the top of your browser window, but instead you’ll need to find
the URL of the AJAX request that’s going on in the background to fetch the data
from the server and load it into the page.
Hartley Brody
---
class: inverse, center, middle
# Live demo
---
## Exercise
http://quotes.toscrape.com/ provides quotes for scraping. This site scraping
sandox provides various endpoints that present different scraping challenges.
Try and scrape the first 50 quotes and authors at the following endpoints.
- http://quotes.toscrape.com/scroll
- http://quotes.toscrape.com/js/
First, try using the typical approach with `rvest` to understand what is
going on.
---
## References
1. Scraping Sandbox. (2020). http://toscrape.com/.
2. SelectorGadget: point and click CSS selectors. (2020). Selectorgadget.com.
https://selectorgadget.com/.
3. yusuzech/r-web-scraping-cheat-sheet. (2020).
https://github.com/yusuzech/r-web-scraping-cheat-sheet.
