class: center, middle, inverse, title-slide # Estimation via Bootstrap II ### Yue Jiang ### 03.23.20 --- layout: true <div class="my-footer"> <span> </span> </div> --- ## Announcements - I will post a video lecture accompaying these slides on WarpWire, which is accessible through the class Sakai page. This video will be made available Sunday evening (before class) so you will have the chance to watch prior to our class period. - I will be avilable via Zoom during our regularly assigned class period, US Eastern Time. The section will briefly recap the pre-recorded video and serve as a Q&A session and opportunity to get live feedback on the Application Exercise. - So many more. Please be patient! --- class: center, middle # Review --- ## Terminology **Population**: a group of individuals or objects we are interested in studying **Sample**: a representative (we assume) subset of our population of interest **Parameter**: a numerical quantity derived from the population (almost always unknown) **Statistic**: a numerical quantity derived from a sample <br/> Common population parameters of interest and their corresponding sample statistic: | Quantity | Parameter | Statistic | |--------------------|------------|-------------| | Mean | `\(\mu\)` | `\(\bar{x}\)` | | Variance | `\(\sigma^2\)` | `\(s^2\)` | | Standard deviation | `\(\sigma\)` | `\(s\)` | | Proportion | `\(p\)` | `\(\hat{p}\)` | --- ## What does inference mean? - **Statistical inference** is the process of using sample data to make conclusions about the underlying population the sample came from. - Types of inference: **testing** and **estimation**. - We will continue to focus on estimation. --- ## Confidence intervals A plausible range of values for the population parameter is an interval estimate. One type of interval estimate is known as a **confidence interval**. -- .pull-left[  ] .pull-right[  ] - If we report a point estimate, we probably won’t hit the exact population parameter. - If we report a range of plausible values, we have a good shot at capturing the parameter. --- ## Bootstrapping scheme 1. **Take a bootstrap sample** - a random sample taken with replacement from the original sample, of the same size as the original sample. 2. **Calculate the bootstrap statistic** - a statistic such as mean, median, proportion, slope, etc. computed on the bootstrap samples. 3. **Repeat steps (1) and (2) many times to create a bootstrap distribution** - a distribution of bootstrap statistics. 4. **Calculate the bounds of the XX% confidence interval** as the middle XX% of the bootstrap distribution. --- ## Bootstrap scheme steps 1 - 3 Consider a sample of size `\(n = 3\)`, and suppose we are interested in conducting inference for the population mean. <img src="images/bootstrap_sample.png"> --- ## Package `infer`  ```r library(infer) ``` -- Also, let's set a seed: ```r set.seed(200323) ``` Function `set.seed()` is a base R function that allows us to control R's random number generation. Use this to make your simulation work reproducible. --- class: center, middle # More inference --- ## Small business owner optimism Data is from a Jan. 15-24 nationwide Square/Gallup online survey of small-business owners with annual revenues between $50,000 and $25 million. <br/> U.S. small businesses were asked, "Has your business benefited from the increased small business deduction that resulted from the 2017 tax reform law, or not?" <br/><br/> -- <b> Given the sample data, can we conclude that at least 65% of U.S. small businesses benefited from the 2017 tax reform? </b> --- ## Data ```r library(tidyverse) library(infer) set.seed(03172020) ``` ```r small_business <- read_csv("data/gallup_sb.csv") ``` ```r small_business ``` ``` ## # A tibble: 1,234 x 1 ## benefit ## <chr> ## 1 yes ## 2 yes ## 3 yes ## 4 no ## 5 yes ## 6 yes ## 7 yes ## 8 yes ## 9 yes ## 10 yes ## # ... with 1,224 more rows ``` --- ## Data wrangling What is the survey response distribution of the sample? -- ```r small_business %>% count(benefit) ``` ``` ## # A tibble: 2 x 2 ## benefit n ## <chr> <int> ## 1 no 382 ## 2 yes 852 ``` -- What are the proportions? -- ```r small_business %>% count(benefit) %>% mutate(prop_benefit = n / sum(n)) ``` ``` ## # A tibble: 2 x 3 ## benefit n prop_benefit ## <chr> <int> <dbl> ## 1 no 382 0.310 ## 2 yes 852 0.690 ``` --- ## Conclusion? We see that the sample proportion is 0.69. That is, 69% of small businesses in the sample stated they did benefit from the 2017 tax reform. -- <br/><br/> <b> Can we now conclude: yes, at least 65% of all U.S. small businesses benefited from the 2017 tax reform? </b> -- <br/><br/> Not necessarily! Why not? -- Let's create a confidence interval for the population proportion, `\(p\)`. --- ## Bootstrap confidence interval 1. `specify()` the `response` variable of interest along with what we define as `success`. <br/> ```r small_business %>% * specify(response = benefit, success = "yes") ``` --- ## Bootstrap confidence interval 1. `specify()` the `response` variable of interest along with what we define as `success`. <br/> 2. `generate()` a fixed number of `reps` for bootstrap `type` samples. <br/> ```r small_business %>% specify(response = benefit, success = "yes") %>% * generate(reps = 5000, type = "bootstrap") ``` --- ## Bootstrap confidence interval 1. `specify()` the `response` variable of interest along with what we define as `success`. <br/> 2. `generate()` a fixed number of `reps` for bootstrap `type` samples. <br/> 3. `calculate()` the bootstrapped `stat`. ```r small_business %>% specify(response = benefit, success = "yes") %>% generate(reps = 5000, type = "bootstrap") %>% * calculate(stat = "prop") ``` --- ## Bootstrap confidence interval 1. `specify()` the `response` variable of interest along with what we define as `success`. <br/> 2. `generate()` a fixed number of `reps` for bootstrap `type` samples. <br/> 3. `calculate()` the bootstrapped `stat`. <br/> 4. `summarize()` our results by getting the middle XX% of the bootstrap distribution in order to produce an XX% confidence interval. ```r small_business %>% specify(response = benefit, success = "yes") %>% generate(reps = 5000, type = "bootstrap") %>% calculate(stat = "prop") %>% * summarize(lower_bound = quantile(stat, 0.025), * upper_bound = quantile(stat, 0.975)) ``` ``` ## # A tibble: 1 x 2 ## lower_bound upper_bound ## <dbl> <dbl> ## 1 0.665 0.716 ``` --- ## Conclusion Our 95% confidence interval is `\((0.664, 0.716)\)`. **What can we conclude now?** --- ## Confidence level exploration ``` ## # A tibble: 6 x 4 ## lower_bound mean_p_hat upper_bound confidence_level ## <dbl> <dbl> <dbl> <dbl> ## 1 0.658 0.690 0.724 0.99 ## 2 0.660 0.690 0.721 0.98 ## 3 0.665 0.690 0.716 0.95 ## 4 0.669 0.690 0.712 0.9 ## 5 0.672 0.690 0.709 0.85 ## 6 0.673 0.690 0.707 0.8 ``` -- <br/><br/> **What do you notice?** --- ## Confidence interval interpretation What do we mean when we say, "We are 98% confident that our interval captures the true population parameter."? -- <br/> Suppose we could do all of the following: 1. Take a random sample of size `\(n\)` from our population. 2. Create a bootstrap confidence interval. 3. Repeat steps 1 - 2 ad infinitum. -- Then, we would expect 98% of those confidence intervals we computed would cover the true population parameter's value. However, in practice, we only do steps 1 - 2 once. --- ## Interpretation visualization 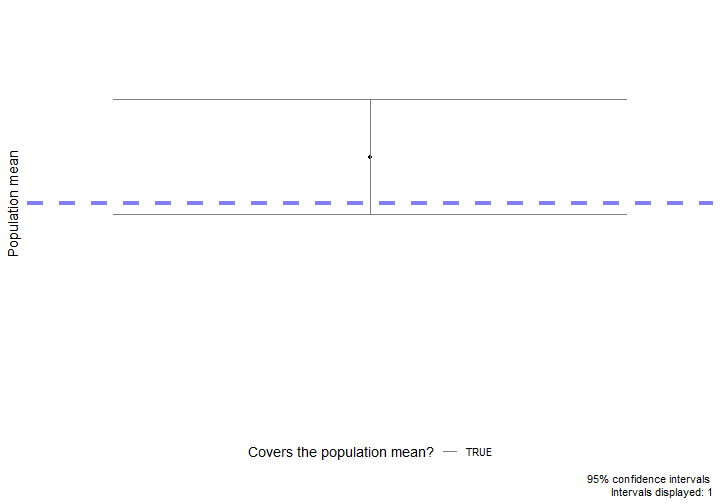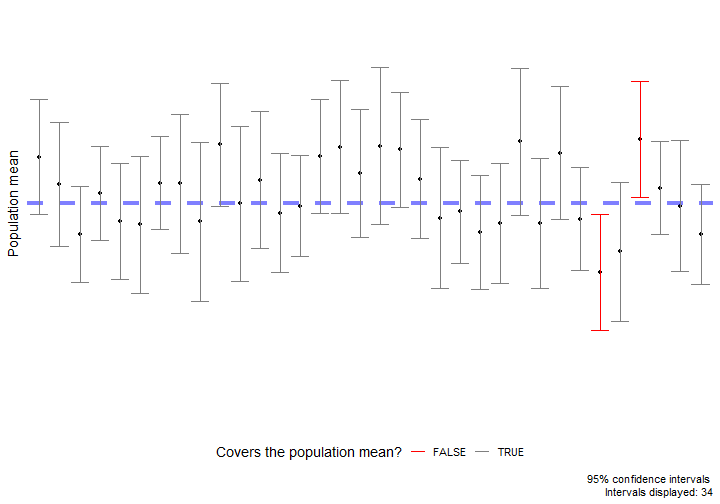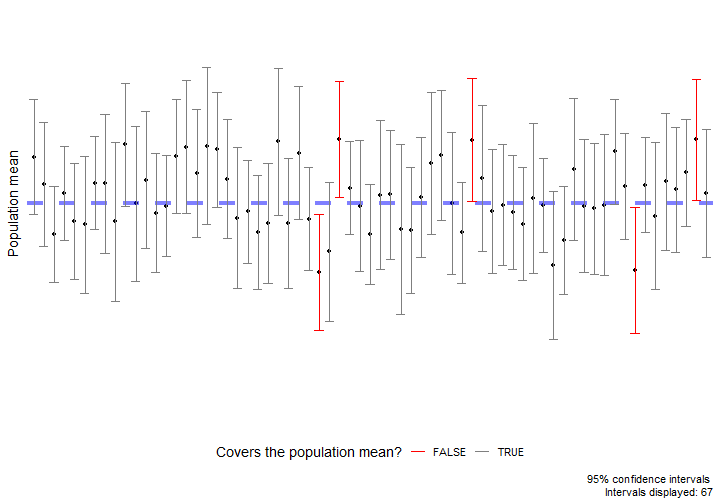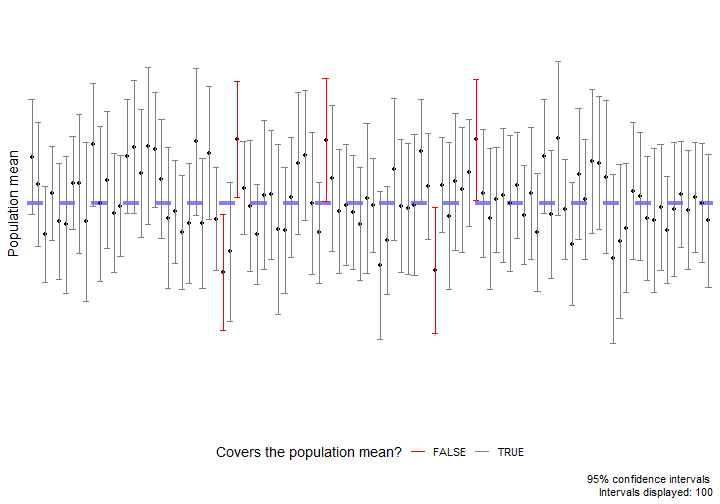<!-- --> --- ## A closer look at `specify()` | Argument | Description | |---------------|----------------------------------------------------------------------------------------------------------------------------------------------| | `x` | data frame | | `formula` | a formula in the form `response ~ explanatory` | | `response` | variable in `x` that is the response variable <br>(not needed if you use argument `formula`) | | `explanatory` | variable in `x` that is the explanatory variable<br>(not needed if you use argument `formula`) | | `success` | level of response considered a success - needed for inference on <br>one proportion, a difference in proportions, and corresponding z stats. | --- ## A closer look at `calculate()` Argument `stat` takes a string for the type of statistic to calculate for each of our bootstrap samples. Below are the available options. <br/> - "mean", "median", "sum", "sd", "prop", "count", - "diff in means", "diff in medians", "diff in props", - "slope", "correlation" - "Chisq", "F", "t", "z" <br/> Depending on the chosen stat, you may need provide a value to the subsequent argument - `order`. --- ## Bootstrap discussion **When can I create bootstrap confidence intervals as we have defined?** - Your original sample is representative of the population, and - your original sample size is not too small. <br/> -- **When should I not create a bootstrap confidence interval?** - Your original sample size is very small (< 5). - You are interested in the maximum or minimum. - The theoretical distribution of the sample statistic is known, and the assumptions are satisfied to conduct meaningful inference. --- ## Bootstrap discussion (continued) - There is no set number of bootstrap samples you should take to create a bootstrap confidence interval. The number you choose should be a function of your sample size and parameter of interest for inference. - Choose a computationally feasible number of bootstrap samples. - Remember, creating a bootstrap confidence interval is a simulation-based inference method. To ensure your work is reproducible, always control R's random number generation process with function `set.seed()`. --- ## Application exercise [https://classroom.github.com/a/L8W1vvBJ](https://classroom.github.com/a/L8W1vvBJ) --- ## References 1. Tidy Statistical Inference. (2020). Infer.netlify.com. Retrieved 29 February 2020, from https://infer.netlify.com/index.html 2. Gallup, I. (2020). Small-Business Owners Highly Engaged in 2020 Election. Gallup.com. Retrieved 6 March 2020, from https://news.gallup.com/poll/284396/small-business-owners-highly-engaged-2020-election.aspx