class: center, middle, inverse, title-slide # Introduction to survival analysis (3) ### Yue Jiang ### Duke University --- ### The DIG Trial <img src="img/02/dig_trial.png" width="120%" /> Investigators compared the **primary outcome** of the number of days from the start of the study to either death or hospitalization from worsening heart failure. --- ### Review: accelerated failure time model An .vocab[accelerated failure time] (AFT) model assumes `\begin{align*} \log(T_i) = \beta_0 + \beta_1x_1 + \beta_2x_2 + \cdots + \beta_px_p + \epsilon_i \end{align*}` where `\(\epsilon_i\)` are commonly assumed to be i.i.d. and follow some specified distribution. Covariates in an AFT model have a multiplicative effect on *time*. For instance, if `\(\beta_k = 0.4\)`, then `\(\exp(\beta_k) \approx 1.5\)`. Holding all else equal, an individual with covariate `\(x_k\)` one unit greater than another is expected to survive approximately 1.5 times longer than the other. --- ### Fitting an AFT model ```r library(survival) aft_w <- survreg(Surv(DWHFDAYS, DWHF) ~ TRTMT + EJF_PER + PREVMI, data = dig, dist = "lognormal") summary(aft_w) ``` ``` ## ## Call: ## survreg(formula = Surv(DWHFDAYS, DWHF) ~ TRTMT + EJF_PER + PREVMI, ## data = dig, dist = "lognormal") ## Value Std. Error z p ## (Intercept) 6.06283 0.12297 49.30 < 2e-16 ## TRTMT 0.55329 0.06741 8.21 2.2e-16 ## EJF_PER 0.05932 0.00385 15.42 < 2e-16 ## PREVMI -0.11991 0.07059 -1.70 0.089 ## Log(scale) 0.82037 0.01636 50.14 < 2e-16 ## ## Scale= 2.27 ## ## Log Normal distribution ## Loglik(model)= -20343.2 Loglik(intercept only)= -20501 ## Chisq= 315.72 on 3 degrees of freedom, p= 3.9e-68 ## Number of Newton-Raphson Iterations: 3 ## n=6799 (1 observation deleted due to missingness) ``` --- ### Visualizing the AFT model <img src="survival-3_files/figure-html/unnamed-chunk-4-1.png" style="display: block; margin: auto;" /> --- ### A similar model for hazards? <img src="survival-3_files/figure-html/unnamed-chunk-5-1.png" style="display: block; margin: auto;" /> --- ### A proportional hazards model `\begin{align*} \lambda(t) &= \lambda_0(t)\exp\left(\beta_1x_1 + \beta_2x_2 + \cdots + \beta_px_p \right) \end{align*}` where `\(\lambda_0\)` is the .vocab[baseline hazard], which describes the hazard function for an individual with `\(\mathbf{X} = \mathbf{0}\)`. A .vocab[proportional hazards] model is a linear model for the log hazard ratio. .question[ How might we interpret `\(\beta\)` terms in such a model? Why is there no intercept term `\(\beta_0\)`? ] --- ### A proportional hazards model `\begin{align*} \lambda(t) &= \lambda_0(t)\exp\left(\beta_1x_1 + \beta_2x_2 + \cdots + \beta_px_p \right) \end{align*}` Covariates in a PH model have a multiplicative effect on *hazards*. For instance, if `\(\beta_k = 0.4\)`, then `\(\exp(\beta_k) \approx 1.5\)`. Holding all else equal, an individual with covariate `\(x_k\)` one unit greater than another is expected to have approximately 1.5 times the *hazard* of the event than the other. This multiplicative effect holds *regardless* of the time `\(t\)`. .question[ Would you rather have a higher linear predictor or a lower linear predictor in a PH model? How does this compare to the AFT model? ] --- ### A proportional hazards model <img src="survival-3_files/figure-html/unnamed-chunk-6-1.png" style="display: block; margin: auto;" /> --- ### Fitting a PH model ```r library(eha) ph_ln <- phreg(Surv(DWHFDAYS, DWHF) ~ TRTMT + EJF_PER + PREVMI, data = dig, dist = "lognormal") ph_ln ``` ``` ## Call: ## phreg(formula = Surv(DWHFDAYS, DWHF) ~ TRTMT + EJF_PER + PREVMI, ## data = dig, dist = "lognormal") ## ## Covariate W.mean Coef Exp(Coef) se(Coef) Wald p ## (Intercept) 4.480 1.109 0.000 ## TRTMT 0.518 -0.290 0.748 0.042 0.000 ## EJF_PER 29.455 -0.038 0.963 0.002 0.000 ## PREVMI 0.645 0.048 1.049 0.044 0.271 ## ## log(scale) 15.421 2.721 0.000 ## log(shape) -1.358 0.123 0.000 ## ## Events 2332 ## Total time at risk 6092212 ## Max. log. likelihood -20339 ## LR test statistic 303.79 ## Degrees of freedom 3 ## Overall p-value 0 ``` .vocab[ How might we interpret the coefficient estimates here? How do they relate to our previous models? ] --- ### The Cox proportional hazards model `\begin{align*} \lambda(t) &= \lambda_0(t)\exp\left(\beta_1x_1 + \beta_2x_2 + \cdots + \beta_px_p \right) \end{align*}` In a parametric survival model (such as ones we've seen), the survival times are assumed to follow a specific distribution, which might be a strong assumption. -- Often times, we only care about the `\(\beta\)` terms and not so much the `\(\lambda_0\)`. Using the concept of partial likelihood, Cox (1972) found that we can "separate" inference for the `\(\beta\)` terms from `\(\lambda_0\)`. The Cox model is a *semiparametric* survival model; `\(\lambda_0(t)\)` (*infinite*- dimensional) is left completely unspecified, with no assumptions made on its shape. (A semi-parametric version of the AFT model also exists, but isn't very popular for reasons we won't get into). --- ### Estimating `\(\beta\)`s .question[ How can we estimate `\(\beta\)` parameters if `\(\lambda_0(t)\)` is infinite-dimensional? ] --- ### Estimating `\(\beta\)`s For now, assume that there are no tied failure times. Suppose we know that there is one failure at time `\(t_j\)`. For this failure time, the contribution to the "likelihood" is the probability that individual `\(j\)` fails, *given* that there is exactly one failure in the risk set at that time: `\begin{align*} P(\text{individual }j\text{ fails} | \text{one failure from }\mathcal{R}(t_j)) \end{align*}` where `\(\mathcal{R}(t_j) = \left\{i: T_i \ge t_j \right\}\)` is the risk set at time `\(t_j\)`. --- ### Estimating `\(\beta\)`s Note that the probability `\begin{align*} P(\text{individual }j\text{ fails} | \text{one failure from }\mathcal{R}(t_j)) \end{align*}` conditions on exactly one failure at time `\(t_j\)`; we don't know who it is! This is equivalent to the probability `\begin{align*} &\mathrel{\phantom{=}} \frac{P(\text{individual }j\text{ fails} | \text{at risk at }t_j)}{\sum_{k \in \mathcal{R}(t_j)}P(\text{individual }k\text{ fails} | \text{at risk at }t_j)}\\ &= \frac{\lambda(t_j | \mathbf{X}_j)}{\sum_{k \in \mathcal{R}(t_j)}\lambda(t_j | \mathbf{X}_k)} \end{align*}` --- ### Estimating `\(\beta\)`s Under proportional hazards, `\(\lambda(t | \mathbf{X}) = \lambda_0(t)\exp(\mathbf{X}^T\beta)\)`. Thus, for each failure time `\(t_j\)`, we have `\begin{align*} &\mathrel{\phantom{=}} \frac{\lambda(t_j | \mathbf{X}_j)}{\sum_{k \in \mathcal{R}(t_j)}\lambda(t_j | \mathbf{X}_k)}\\ &= \frac{\lambda_0(t_j)\exp(\mathbf{X}_j^T\beta)}{\sum_{k \in \mathcal{R}(t_j)}\lambda_0(t_j)\exp(\mathbf{X}_k^T\beta)}\\ &= \frac{\exp(\mathbf{X}_j^T\beta)}{\sum_{k \in \mathcal{R}(t_j)}\exp(\mathbf{X}_k^T\beta)} \end{align*}` --- ### Estimating `\(\beta\)`s If there are `\(J\)` total failure times, the "likelihood" is thus the product over all possible failure times: `\begin{align*} \mathcal{L}^\star(\beta | \mathbf{X}) &= \prod_{j = 1}^J \frac{\exp(\mathbf{X}_j^T\beta)}{\sum_{k \in \mathcal{R}(t_j)}\exp(\mathbf{X}_k^T\beta)} \end{align*}` Note that we can maximize this quantity with respect to `\(\beta\)` terms *without* having to estimate (or even specify) the baseline hazard `\(\lambda_0(t)\)`! --- ### The Cox proportional hazards model `\begin{align*} \lambda(t) &= \lambda_0(t)\exp\left(\beta_1x_1 + \beta_2x_2 + \cdots + \beta_px_p \right) \end{align*}` - Fewer assumptions than fully parametric models, but still requires PH assumption - By far the most commonly used regression model for survival data - Attractive interpretations using hazard ratios - Can be extended to accommodate time-varying covariates, recurrent events, etc. --- ### Fitting the Cox PH model ```r coxm1 <- coxph(Surv(DWHFDAYS, DWHF) ~ TRTMT + EJF_PER + PREVMI, data = dig) summary(coxm1) ``` ``` ## Call: ## coxph(formula = Surv(DWHFDAYS, DWHF) ~ TRTMT + EJF_PER + PREVMI, ## data = dig) ## ## n= 6799, number of events= 2332 ## (1 observation deleted due to missingness) ## ## coef exp(coef) se(coef) z Pr(>|z|) ## TRTMT -0.289745 0.748454 0.041666 -6.954 3.55e-12 *** ## EJF_PER -0.038061 0.962654 0.002381 -15.985 < 2e-16 *** ## PREVMI 0.047921 1.049087 0.043638 1.098 0.272 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## exp(coef) exp(-coef) lower .95 upper .95 ## TRTMT 0.7485 1.3361 0.6898 0.8121 ## EJF_PER 0.9627 1.0388 0.9582 0.9672 ## PREVMI 1.0491 0.9532 0.9631 1.1428 ## ## Concordance= 0.605 (se = 0.006 ) ## Likelihood ratio test= 304.4 on 3 df, p=<2e-16 ## Wald test = 302.5 on 3 df, p=<2e-16 ## Score (logrank) test = 306.2 on 3 df, p=<2e-16 ``` .question[ How might we interpret these coefficients? How do they compare to our previous models? ] --- ### Fitting the Cox PH model One strength of the Cox model is that we can ignore estimation of `\(\lambda_0\)` completely (it doesn't matter for valid inference on the `\(\beta\)`s). If we want to estimate survival probabilities, then we must estimate the baseline hazard. A non-parametric estimate of the cumulative hazard (the .vocab[Breslow estimator]) is implemented by the `basehaz` function in the `survival` package by: `\begin{align*} \hat{\Lambda}_0(t) = \sum_{i:t_{(i)} < t} \frac{1}{\sum_{k \in \mathcal{R}_i} \exp(\mathbf{X}_k\beta)} \end{align*}` We can then estimate survival in the Cox model by: `\begin{align*} \hat{S}(t|\mathbf{X}) = \exp(-\exp(\mathbf{X}\beta) \hat{\Lambda}_0(t)) \end{align*}` --- ### Cox model diagnostics Recall the inverse CDF result: if `\(T_i\)` has survival function `\(S_i(t)\)`, then `\(S_i(T_i)\)` should have a uniform distribution on (0, 1) and `\(\Lambda_i(T_i)\)` should follow Exp(1) distribution. Thus, if the model is correct, then the estimated cumulative hazard `\(\hat{\Lambda}\)` at observed times should be a censored sample from Exp(1). These `\(\hat{\Lambda}_i(Y_i)\)` are known as .vocab[Cox-Snell residuals]. -- Plotting `\(\log(-\log\hat{S}(Y_i))\)` against `\(\log(Y_i)\)` should thus follow a straight line through the origin at a 45-degree angle. Although Cox-Snell residuals can also be used for other models (e.g., checking whether distribution specified in AFT model is appropriate), they're not too useful in practice (for a variety of reasons). --- ### Cox model diagnostics To assess PH assumption, we can examine .vocab[Schoenfeld residuals]. Intuitively, each Schoenfeld residual is the difference between the observed covariate and the expected covariate for each observed failure, conditioned on the risk set at that time. In plotting Schoenfeld residuals vs. survival times, we expect to see them randomly distributed around 0. --- ### Cox model diagnostics .vocab[Martingale residuals] are based on the difference between observed number of events up until time `\(Y_i\)` and the expected count based on the fitted model. .vocab[Deviance residuals] are a normalized transformation of the martingale residuals that correct their skewness. They should be randomly distributed around mean 0 with a variance of 1. In practice, these residuals are useful for finding potential outliers: negative values "lived longer than expected" and positive values "died too soon." --- ### Cox model diagnostics ```r library(survminer) ggcoxdiagnostics(coxm1, type = "schoenfeld") ``` <!-- --> --- ### Cox model diagnostics ```r library(survminer) ggcoxdiagnostics(coxm1, type = "deviance", linear.predictions = F) ``` 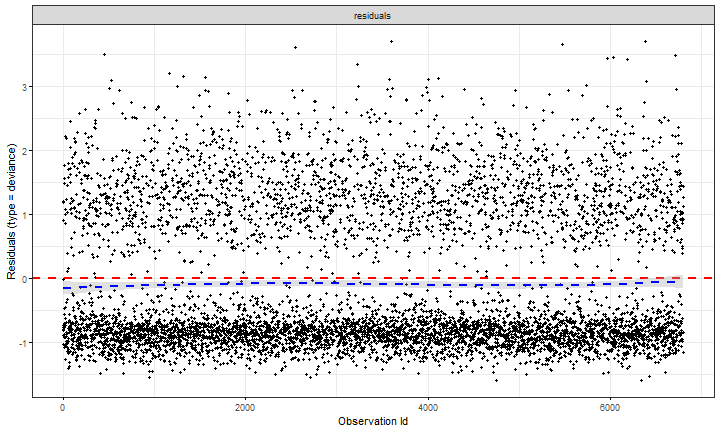<!-- -->